
Loftus Peak’s Tom Keir writes:
You would be forgiven for thinking that Artificial Intelligence (AI) began in 2022 with ChatGPT, however the latest Nobel Prizes leave no room for confusion. AI models beyond Large Language Models (LLMs) can be extremely useful. Not only that, but the way in which models are developed gives us a peek into the future roll out of AI across industries and hardware.
AlphaFold is a reinforcement learning model – don’t forget it
Reinforcement learning models rely on having a robust mechanism for validating outputs as well as sufficient quality and quantity of training data. The data produces a model that can then perform self-evaluation according to its validation mechanism.
In the case of AlphaFold, all known proteins have similar structural features. The chemical properties that determine these features are also known. This means that Alphabet did not need to devise a validation mechanism – it already existed. Combining this mechanism with the data resulted in a model capable of discovering new proteins that could exist in the real world. Subsequently the number of known proteins exploded.
The size of the protein data bank has grown from 200,000 to 214,000,000
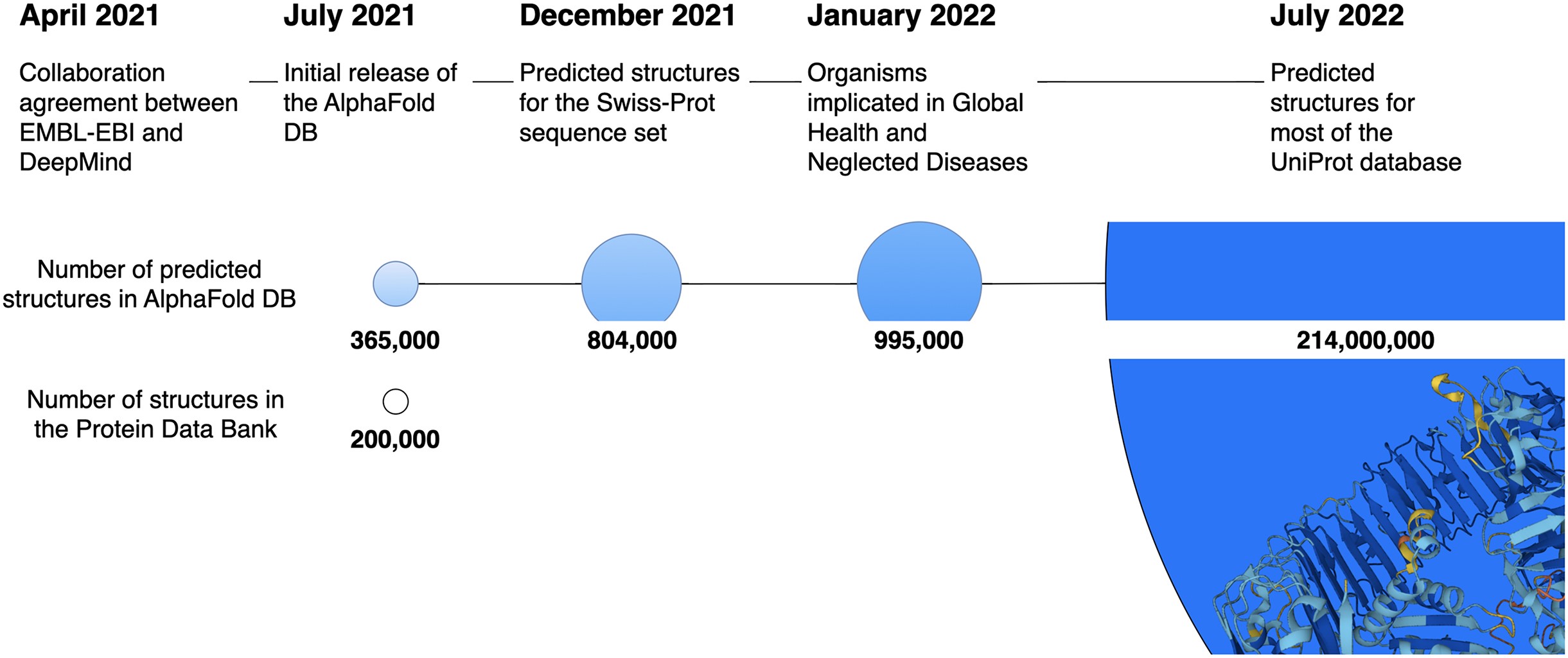
Source: Oxford Academic
This model was 15 years in the making
It was David Baker, in 2003, (the third and only non-Alphabet winner of the 2024 Chemistry Nobel Prize) who programmatically discovered a protein. AlphaFold 1 was released in 2018. Unlike LLMs, training was not only bottlenecked by computational limitations, there was a lack of AI techniques and disorganised training data.
The AlphaFold 2 model released in 2021 was trained for ~2 weeks on 128 Broadcom TPUv3s. This involved a modest amount of compute three years ago and is dwarfed by the LLMs being trained today. For reference, Alphabet’s recent Gemini 1.5 LLM was trained on multiple TPUv4s pods, each comprising 4096 chips.
Incremental AI is the norm, not the exception
For many AI use cases (with the notable exception of LLMs), performance has improved incrementally over time. This is because the compute has had to improve along with use cases, specific model architectures and the organisation of training data.
So what happens to semiconductors?
The fact that many AI applications incur relatively low computational costs is not a reason to be bearish on semiconductors. The AI of keenest market interest, generative AI (including the LLMs), would still benefit significantly from more compute capability. This helps explain why Nvidia is valued above US$3 trillion.
Language model training will likely always be on the cloud, but the economics of inference on phones and computers (A.K.A. edge devices) are compelling. Think of it from Google or Microsoft’s perspective. Customers currently pay to use AI models which are then inferenced over the cloud using chips, land and electricity paid for by the cloud provider. If the AI tool was edge native, the cloud provider merely trains the model and then sells it to a customer who pays for their own personal chip (inside their phone or computer) and their own electricity.
Models of all stripes will keep improving, especially through reinforcement learning
Alphabet’s AlphaFold model was a pioneer in reinforcement learning. This is part of why the model was so impressive in 2018. Today, the same reinforcement learning is being used in other non-LLM use cases in a manner that is structurally similar to AlphaFold. Simultaneously, LLMs are being used to expand the frontier of problems that can be solved with reinforcement learning.
By using language models for self-evaluation and self-programming, future reinforcement learning models do not need a tailor-made validation mechanism (or a pre-existing one in the case of protein folding). Instead, the LLM itself can be the mechanism. This means what Alphabet has achieved for proteins is theoretically achievable for any problem with inputs expressed in human language or computer code – two things LLMs produce relatively well.
The key takeaway
We contend that the disruptive impact of AI is only in the very early stages, and the landscape is becoming increasingly complicated. A growing number of companies provide semiconductor tools that can be used for AI and more beneficiaries have emerged building business specific AI models. Not all the AI exposed companies will benefit equally. In this expanding landscape, valuations are vital – providing a framework for investment across the full AI lifecycle.
Share this Post